###1. struct sk_buff
sk_buff是Linux网络代码中最重要的结构体之一。它是Linux在其协议栈里传送的结构体,也就是所谓的“包”,在其中包含了各层协议的头部的指针,比如ethernet, ip ,tcp ,udp等等,linux中还定义了一堆sk_buff的相关操作函数
###2. sk_buff 成员
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next; // 用于串联struct sk_buff, 形成双向链表
struct sk_buff *prev; // 用于串联struct sk_buff, 形成双向链表
ktime_t tstamp; // 数据到达的时间戳, 通常由 netif_rx() 调用 net_timestamp() 设置
struct sock *sk; // 该数据对应的socket
struct net_device *dev; // 发送数据包时的出口网络设备, 目的地址为本地的数据包使用“lo”接口
......
unsigned int len, // 实际数据的长度
data_len; // 数据的长度
__u16 mac_len, // 链路层数据头的长度
hdr_len; // clone的sk_buff的可写数据头的长度
......
__be16 protocol; // 链路层帧的协议类型,如ETH_P_ARP, 由driver标识
......
int skb_iif; // 接收到该数据包的网络接口的编号
......
sk_buff_data_t inner_transport_header; //内部的传输层协议头
sk_buff_data_t inner_network_header; //内部的网络层协议头
sk_buff_data_t inner_mac_header; //内部的链路层协议头
sk_buff_data_t transport_header; //传输层协议头
sk_buff_data_t network_header; //网络层协议头
sk_buff_data_t mac_header; //链路层协议头
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail; //tail 指针,下一节详细解释
sk_buff_data_t end; //end 指针,下一节详细解释
unsigned char *head, //head 指针,下一节详细解释
*data; //data 指针,下一节详细解释
unsigned int truesize; //data buffer和sk_buff的总大小
atomic_t users; //sk_buff的引用计数
};
###3. sk_buff的分配
linux kernel中提供两种api用于 sk_buff和数据的分配
struct sk_buff *alloc_skb(unsigned int size, gfp_t priority);
struct sk_buff *dev_alloc_skb(unsigned int length);
sk_buff和数据缓冲区是2种不同的实例, 因此, 涉及到2次内存分配: 从告诉缓存中分配sk_buff; 分配对应的数据缓冲区
alloc_dev() 的priority参数用于指定内存分配的方式:
- GFP_ATOMIC:分配内存优先级高,不会睡眠, 用于中断上下文
- GFP_KERNEL:常用的方式,可能会阻塞
dev_alloc_skb()默认使用 GFP_ATOMIC 的方式来分配内存, 尽量不要在非中断上下文中使用
####3.1 skb_shared_info结构
在数据缓存区的末尾,即end指针所指向的地址起紧跟着有一个skb_shared_ info结构,保存了数据块的附加信息
struct skb_shared_info {
unsigned char nr_frags;
__u8 tx_flags;
unsigned short gso_size;
/* Warning: this field is not always filled in (UFO)! */
unsigned short gso_segs;
unsigned short gso_type;
struct sk_buff *frag_list;
struct skb_shared_hwtstamps hwtstamps;
__be32 ip6_frag_id;
/*
* Warning : all fields before dataref are cleared in __alloc_skb()
*/
atomic_t dataref;
/* Intermediate layers must ensure that destructor_arg
* remains valid until skb destructor */
void * destructor_arg;
/* must be last field, see pskb_expand_head() */
skb_frag_t frags[MAX_SKB_FRAGS];
};
其中
- dataref : 数据缓冲区的引用计数, 例如skb_clone会克隆一个sk_buff, 和原始的sk_buff指向同一个数据缓冲区
####3.2 sk_buff 高速缓存
在skb_init()中申请了两个用于分配sk_buff (不包含数据缓冲区)的高速缓存
void __init skb_init(void)
{
skbuff_head_cache = kmem_cache_create("skbuff_head_cache",
sizeof(struct sk_buff),
0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC,
NULL);
skbuff_fclone_cache = kmem_cache_create("skbuff_fclone_cache",
(2*sizeof(struct sk_buff)) +
sizeof(atomic_t),
0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC,
NULL);
}
两个高速缓存:
- skbuff_head_cache : 一般情况下, 从该缓存分配 sk_buff, 每次分配的大小为 sizeof(sk_buff)
- skbuff_fclone_cache : 若知道sk_buff可能或被克隆, 则从该缓存来分配sk_buff, 每次分配两个sk_buff, 大小为 2*sizeof(sk_buff) + sizeof(atomic_t), 额外的一个引用用于标识这一对sk_buff有几个被使用, 其值可以为 0,1,2
###4. sk_buff的释放
linux kernel提供2个api用于sk_buff的释放
void kfree_skb(struct sk_buff *skb);
#define dev_kfree_skb(a) consume_skb(a)
void dev_kfree_skb_irq(struct sk_buff *skb);
void dev_kfree_skb_any(struct sk_buff *skb);
kfree_skb() 和 dev_kfree_skb() 都是调用 __kfree_skb()来完成sk_buff的释放,他们会修改sk_buff的引用计数sk_buff.users,只有当 sk_buff.users为0时, 才完成真正的释放工作
- linux kernel 里面使用 kfree_skb(),
- 设备驱动里面最好使用 dev_kfree_skb(),
- 中断上下文中使用 dev_kfree_skb_irq()
- dev_kfree_skb_any() 在中断和非中断上下文中都可使用, 内部会根据需要自己决定调用 dev_kfree_skb() 或者 dev_kfree_skb_irq()
###5. sk_buff 的数据缓冲区指针
分配sk_buff时, 会涉及到两次内存分配, 一块用于存放 sk_buff, 另一块数据缓冲区用于存放数据包, sk_buff中有4个成员指针(head, end, data, tail)会指向数据缓冲区
先看上层协议发送数据这种情况
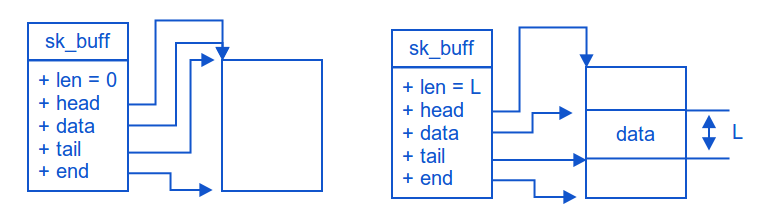
- 如图左, 首先, 分配一个sk_buff以及data buffer
- sk_buff.head 指向data buffer的起始位置, 并且这一指针是固定不变的
- sk_buff.end 指向data buffer的起始位置, 并且这一指针是固定不变的
- sk_buff.data 指向实际存放的数据的起始位置, 因现在没有存放数据,和sk_buff.head相同
- sk_buff.tail 指向实际存放的数据的结束位置, 因现在没有存放数据,和sk_buff.head相同
- sk_buff.len 实际存放数据的长度, 因现在没有存放数据, 故为0
- 如图右, 在data buffer中, 预留一部分空间给下层协议头, 然后填入数据
- sk_buff.data 指向实际存放的数据的起始位置, sk_buff.head和sk_buff.data之间是为下层协议预留的空间
- sk_buff.tail 指向实际存放的数据的结束位置
- sk_buff.len 实际存放数据的长度
如上面所示的方式, sk_buff在各层之间传递时, 通过修改 sk_buff.data 和 sk_buff.tail 就可以索引各协议层的数据, 同样有一套api用于修改sk_buff.data和sk_buff.tail指针(下一小节会详细说明)
在收包时, 每一层的协议栈, 在完成本层的处理之后, 在将sk_buff 发给上层之前, 会将 sk_buff.data指向本层协议的协议头的尾部, 即上层协议收到sk_buff时, sk_buff.data指向该层的协议头, 发送的过程则与此相反
另外, 需要注意的是, sk_buff中几个标识长度的成员
- sk_buff.len : 标识实际数据的长度, 即 sk_buff.tail - sk_buff.data, 这一值在各协议层传递时会有变化
- sk_buff.data_len : data buffer的长度,在分配好之后, 这一值不会变化
- sk_buff.truesize : sk_buff结构体和data buffer的总长度,在分配好之后, 这一值不会变化
####5.1 修改 sk_buff的数据缓冲区指针
linux kernel 中有一套api用于修改sk_buff.data和sk_buff.tail指针
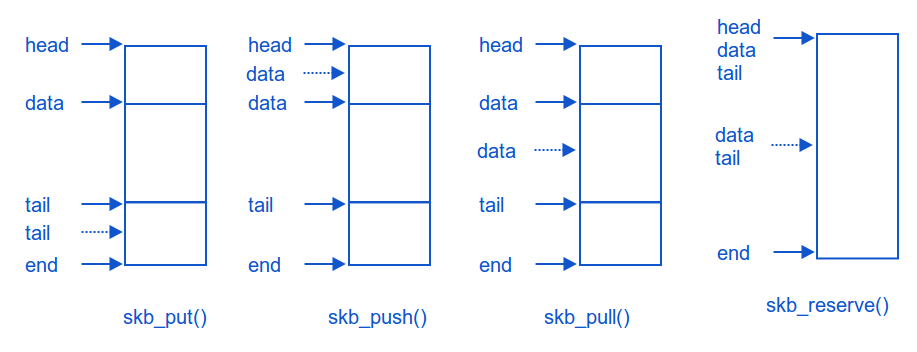
unsigned char *skb_put(struct sk_buff *skb, unsigned int len);
unsigned char *skb_push(struct sk_buff *skb, unsigned int len);
unsigned char *skb_pull(struct sk_buff *skb, unsigned int len);
inline void skb_reserve(struct sk_buff *skb, int len);
- skb_push() : 用于扩展实际的数据区的尾部, 即增加 sk_buff.tail 的值,同时修改sk_buff.len, 然后返回旧的 sk_buff.tail的值
- skb_push() : 用于扩展实际的数据区的首部, 即减小 sk_buff.data 的值,同时修改sk_buff.len, 然后返回修改后的 sk_buff.data的值, 常用于发送数据时, 数据包从上层协议传递到下层时, 添加下层的协议头
- skb_pull() : 用于扩展实际的数据区的首部, 即减小 sk_buff.data 的值,同时修改sk_buff.len, 然后返回修改后的 sk_buff.data的值,常用于接收数据时, 数据包从下层协议传递到上层时, 剥离下层的协议头
- skb_reserve() : 用于在实际数据区的首部预留空间, 即同时增加 sk_buff.data 和 sk_buff.tail, 常用在于在填充协议数据前, 为下层协议头预留空间
####5.2 获取sk_buff的数据缓冲区指针
static inline unsigned char *skb_end_pointer(const struct sk_buff *skb) //获取sk_buff.end
static inline unsigned char *skb_tail_pointer(const struct sk_buff *skb) //获取sk_buff.tail
static inline void skb_reset_tail_pointer(struct sk_buff *skb) //sk_buff.tail = sk_buf.data
static inline void skb_set_tail_pointer(struct sk_buff *skb, const int offset) //设置 sk_buff.tail 到 sk_buff.data的偏移
static inline unsigned int skb_headroom(const struct sk_buff *skb) //sk_buff.head到sk_buff.data之间的空间大小
static inline int skb_tailroom(const struct sk_buff *skb) //sk_buff.tail到sk_buff.end之间的空间大小
static inline int skb_availroom(const struct sk_buff *skb) //sk_buff.tail到sk_buff.end之间由sk_stram_alloc()分配的空间的大小
###6. sk_buff的协议头指针
sk_buff.xxx_header保存了各协议层的header的指针
- mac_header : 链路层帧头指针
- network_header : 网络层数据包头
- transport_header : 传输层数据报头
- inner_mac_header : 内部的链路层帧头指针, 用于处理网络隧道
- inner_network_header : 内部的链路层帧头指针, 用于处理网络隧道
- inner_transport_header : 内部的传输层数据报头, 用于处理网络隧道
接收数据时, 由于第n层协议从第n-1层协议接收到 sk_buff时, sk_buff.data指向第n层的协议头, 因此第n层的协议负责将该层的协议头指针初始化为 sk_buff.data, 例如, ip层(网络层)在接收到sk_buff后负责将sk_buff.network_header 初始化为 sk_buff.data
linux kernel中提供了相关的api来获取/设置这些 xxx_header 指针
static inline unsigned char *skb_mac_header(const struct sk_buff *skb) //获取k_buff.mac_header
static inline unsigned char *skb_network_header(const struct sk_buff *skb) //获取sk_buff.network_header
static inline unsigned char *skb_transport_header(const struct sk_buff *skb) //获取sk_buff.transport_header
static inline void skb_set_mac_header(struct sk_buff *skb, const int offset //设置 sk_buff.mac_header 到 sk_buff.data的偏移
static inline void skb_set_network_header(struct sk_buff *skb, const int offset) //设置 sk_buff.network_header 到 sk_buff.data的偏移
static inline void skb_set_transport_header(struct sk_buff *skb,const int offset) //设置 sk_buff.transport_header 到 sk_buff.data的偏移
static inline void skb_reset_mac_header(struct sk_buff *skb) //skb->mac_header = skb->data
static inline void skb_reset_network_header(struct sk_buff *skb) //skb->network_header = skb->data
static inline void skb_reset_transport_header(struct sk_buff *skb) //skb->transport_header = skb->data
static inline int skb_mac_header_was_set(const struct sk_buff *skb) //检查是否初始化了skb->mac_header
static inline bool skb_transport_header_was_set(const struct sk_buff *skb) //检查是否初始化了skb->transport_header
static inline unsigned char *skb_inner_mac_header(const struct sk_buff *skb) //获取sk_buff.inner_mac_header
static inline unsigned char *skb_inner_network_header(const struct sk_buff *skb) //获取sk_buff.inner_network_header
static inline unsigned char *skb_inner_transport_header(const struct sk_buff *skb) //获取sk_buff.inner_transport_header
static inline void skb_set_inner_mac_header(struct sk_buff *skb, const int offset) //设置 sk_buff.inner_mac_header 到 sk_buff.data的偏移
static inline void skb_set_inner_network_header(struct sk_buff *skb, const int offset) //设置 sk_buff.inner_network_header 到 sk_buff.data的偏移
static inline void skb_set_inner_transport_header(struct sk_buff *skb, const int offset) //设置 sk_buff.inner_transport_header 到 sk_buff.data的偏移
static inline void skb_reset_inner_mac_header(struct sk_buff *skb) //skb->inner_mac_header = skb->data
static inline void skb_reset_inner_network_header(struct sk_buff *skb) //skb->inner_network_header = skb->data
static inline void skb_reset_inner_transport_header(struct sk_buff *skb) //skb->inner_transport_header = skb->data
static inline void skb_reset_inner_headers(struct sk_buff *skb) //reset inner_mac_header, inner_network_header, inner_transport_header
static inline void skb_reset_mac_len(struct sk_buff *skb)
当然, 还有一些包装好的函数可以直接获取各层的协议头
static inline struct ethhdr *eth_hdr(const struct sk_buff *skb)
{
return (struct ethhdr *)skb_mac_header(skb);
}
static inline struct iphdr *ip_hdr(const struct sk_buff *skb)
{
return (struct iphdr *)skb_network_header(skb);
}
static inline struct icmphdr *icmp_hdr(const struct sk_buff *skb)
{
return (struct icmphdr *)skb_transport_header(skb);
}
static inline struct tcphdr *tcp_hdr(const struct sk_buff *skb)
{
return (struct tcphdr *)skb_transport_header(skb);
}
static inline struct udphdr *udp_hdr(const struct sk_buff *skb)
{
return (struct udphdr *)skb_transport_header(skb);
}
......
其它的sk_buff 指针相关的api
static inline int pskb_may_pull(struct sk_buff *skb, unsigned int len) //检测sk_buff中的数据是否有指定的长度
static inline void skb_pop_mac_header(struct sk_buff *skb) //skb->mac_header = skb->network_header
static inline void skb_probe_transport_header(struct sk_buff *skb, const int offset_hint) //若skb->transport_header 未初始化则初始化它
static inline void skb_mac_header_rebuild(struct sk_buff *skb)
###8. sk_buff 的数据缓冲区添加/删除/拆分
static inline int skb_add_data(struct sk_buff *skb, char __user *from, int copy)
void skb_trim(struct sk_buff *skb, unsigned int len)
static inline int pskb_trim(struct sk_buff *skb, unsigned int len)
void skb_split(struct sk_buff *skb, struct sk_buff *skb1, const u32 len)
- skb_add_data() : 在缓冲区尾部(sk_buff.tail所指的位置)添加数据, 其中
- from : 源数据的起始位置
- copy : 添加的数据的长度
- skb_trim() : 删除sk_buff数据区尾部的数据(即 移动sk_buff.tail 向 sk_buff.data 靠拢), 只能处理线性存储数据的sk_buff
- len : 截取后, 新的数据区长度, 若小于原始长度则不执行操作
- pskb_trim() : 同skb_trim(), 但是pskb_trim()还能够处理非线性存储数据的 sk_buff
- skb_split() : 根据指定长度拆分skb,使得原skb中的数据长度为指定的长度len,而剩下的数据保存到拆分得到的skb1中, 当拆分数据的长度小于线性数据长度时比较容易处理,直接拆分线性数据区即可,若拆分数据的长度大于线性数据长度,则需要拆分非线性区域中的数据
- skb : 原始的skb
- skb1 : 保存拆分后, 剩余数据的skb
- len : 拆分后, 原始skb中应当保留的数据长度
###9. sk_buff 的克隆和复制
如果一个SKB会被不同的用户独立操作(例如一个接收包程序要把该包传递给多个处理函数或者网络模块),而这些用户可能只是修改SKB描述符中的某些字段值,例如 mac_header, data等, 内核没有必要为每个用户复制一份完整的SKB描述及其相应的数据缓存区,而会为了提高性能,只复制SKB描述符,同时增加数据缓存区的引用计数,以免共享数据被提前释放, 这一过程由 skb_clone() 完成
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask)
克隆后, 原始的sk_buff.cloned和克隆的sk_buff.cloned都会被设置为1,克隆的sk_buff.users值会被置为1,这样在第一次释放时就会释放掉,同时将数据缓存区引用计数dataref递增1,因为又多了一个克隆的sk_buff指向它
可以使用 skb_cloned() 来检查一个sk_buff是否被clone
static inline int skb_cloned(const struct sk_buff *skb)
一个sk_buff被克隆后,该sk_buff对应的数据缓存区中的内容就不能再被修改,这也意味着访问数据的函数没有必要加锁
当一个函数不仅要修改sk_buff,而且还要修改数据缓存区中的数据时,就需要同时复制数据缓存区, 这一过程可以使用 skb_copy() 和 pskb_copy() 来完成
struct sk_buff *skb_copy(const struct sk_buff *skb, gfp_t gfp_mask)
static inline struct sk_buff *pskb_copy(struct sk_buff *skb, gfp_t gfp_mask)
当sk_buff为非线性存储数据时, 则只能使用 skb_cpoy()
###10. sk_buff 双向链表
sk_buff被串联成一个复杂的双向链表,由struct sk_buff_head 引用, 在它们中有next和prev指针,分别指向链表的下一个节点和前一个节点
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
......
};
###11. sk_buff 队列操作
linux kernel为 sk_buff_head 指向的双向链表提供了一套队列操作接口:
初始化一个sk_buff队列, 即 sk_buff_head.len = 0, 并将 sk_buff_head.next 和 sk_buff_head.prev 指向 sk_buff_head 自身
static void skb_queue_head_init(struct sk_buff_head *list)
添加 sk_buff 到队列头/尾
void skb_queue_head(struct sk_buff_head *list, struct sk_buff *newsk);
void skb_queue_tail(struct sk_buff_head *list, struct sk_buff *newsk);
从 sk_buff 队列头/尾取出一个sk_buff
struct sk_buff *skb_dequeue(struct sk_buff_head *list)
struct sk_buff *skb_dequeue_tail(struct sk_buff_head *list);
在队列中插入sk_buff
skb_insert(struct sk_buff *old, struct sk_buff *newsk, struct sk_buff_head *list);
将队列变为空(事实上, 循环对队列调用 skb_dequeue(), 然后对每一个sk_buff调用kfree_skb() )
void skb_queue_purge(struct sk_buff_head *list);
遍历队列中指定的sk_buff及其之后的sk_buff
skb_queue_walk(queue, skb)
skb_queue_walk_safe(queue, skb, tmp)
skb_queue_walk_from(queue, skb)
skb_queue_walk_from_safe(queue, skb, tmp)
遍历队列中指定的sk_buff及其之前的sk_buff
skb_queue_reverse_walk(queue, skb)
skb_queue_reverse_walk_safe(queue, skb, tmp)
skb_queue_reverse_walk_from_safe(queue, skb, tmp)
连接两个sk_buff队列
/* 将 list 所指的sk_buff 链表插入到 head 所指的链表的头部 */
void skb_queue_splice(const struct sk_buff_head *list, struct sk_buff_head *head)
/* 同 skb_queue_splice() 将 list 所指的sk_buff 链表插入到 head 所指的链表的头部, 另外将 list 链表清空 */
void skb_queue_splice_init(struct sk_buff_head *list, struct sk_buff_head *head)
/* 将 list 所指的sk_buff 链表插入到 head 所指的链表的尾部 */
void skb_queue_splice_tail(const struct sk_buff_head *list, struct sk_buff_head *head)
/* 同 skb_queue_splice_tail() 将 list 所指的sk_buff 链表插入到 head 所指的链表的尾部, 另外将 list 链表清空 */
void skb_queue_splice_tail_init(struct sk_buff_head *list, struct sk_buff_head *head)
其它操作
__u32 skb_queue_len(const struct sk_buff_head *list_)
int skb_queue_empty(const struct sk_buff_head *list)
bool skb_queue_is_last(const struct sk_buff_head *list, const struct sk_buff *skb)
bool skb_queue_is_first(const struct sk_buff_head *list, const struct sk_buff *skb)
struct sk_buff *skb_queue_next(const struct sk_buff_head *list, const struct sk_buff *skb)
struct sk_buff *skb_queue_prev(const struct sk_buff_head *list, const struct sk_buff *skb)
###12. linux中的sk_buff队列
在linux中,为每一个cpu都维护了一个sk_buff队列(sk_buff_head指向的双向链表),由于是每个cpu都有一个队列,因此在不同的cpu之间我们就不需要任何锁来控制sk_buff队列 的并发处理
struct softnet_data {
......
struct sk_buff *completion_queue;
struct sk_buff_head process_queue;
......
unsigned int dropped;
struct sk_buff_head input_pkt_queue;
struct napi_struct backlog;
};
其中
- completion_queue : 发送完成后的sk_buff放在这一队列中等待被回收
- input_pkt_queue : 用于保存待处理的接收到的sk_buff
- dropped : 被丢弃的数据包的计数
- process_queue : 用于保存正在处理的接收到的sk_buff
可以通过如下的方式获取per-cpu的 softnet_data, 第二个参数为cpu的id
per_cpu(softnet_data, cpu);
####13 sk_buff在sk_buff队列中的流动
网络设备驱动填充好sk_buff后, 调用 netif_rx() 将sk_buff交给linux的网络协议栈来处理
netif_rx()
enqueue_to_backlog()
int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail)
{
......
sd = &per_cpu(softnet_data, cpu);
......
if (skb_queue_len(&sd->input_pkt_queue) <= netdev_max_backlog) {
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
......
return NET_RX_SUCCESS;
}
......
____napi_schedule(sd, &sd->backlog);
......
goto enqueue;
}
sd->dropped++;
......
atomic_long_inc(&skb->dev->rx_dropped);
......
return NET_RX_DROP;
}
- 首先, 获取per-cpu的softnet_data
- 若 input_pkt_queue 队列中 sk_buff数目小于netdev_max_backlog(通常为1000)
- 若 input_pkt_queue 队列非空, 则直接将sk_buff入队到input_pkt_queue队列的尾部然后返回
- 若 input_pkt_queue 队列为空, 则先唤醒软中断NET_RX_SOFTIRQ来处理input_pkt_queue中的包,然后将sk_buff入队到input_pkt_queue队列的尾部再返回
- 如果input_pkt_queue队列中sk_buff数目大于netdev_max_backlog(通常为1000), 则直接丢弃sk_buff, 同时
- 增加 softnet_data.dropped 计数
- 增加 skb->dev->rx_dropped 计数
____napi_schedule()用于触发软中断 NET_RX_SOFTIRQ 来处理 per-cpu 的 softnet_data.input_pkt_queue 队列中的skb, 该软中断的注册过程为
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
因此, 其处理函数为 net_rx_action()
void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = &__get_cpu_var(softnet_data);
......
int work, weight;
struct napi_struct *n;
.....
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
......
work = n->poll(n, weight);
......
}
对于不使用NAPI的net_device 来说, napi_struct.poll 指向 process_backlog(), 而 使用NAPI的驱动则需要自己注册poll 函数, 但是最终还是会调用 process_backlog()
int process_backlog(struct napi_struct *napi, int quota)
{
......
while (work < quota) {
......
while ((skb = __skb_dequeue(&sd->process_queue))) {
......
__netif_receive_skb(skb);
......
}
......
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen)
skb_queue_splice_tail_init(&sd->input_pkt_queue, &sd->process_queue);
......
}
......
}
在 process_backlog()中 :
- 先将 process_queue 队列中的sk_buff依次出队, 通过__netif_receive_skb(skb)发送给协议栈,依次进行 链路层/网络层/传输层 等的处理
- 再将 input_pkt_queue 队列添加到process_queue队列的尾部, 然后清空 input_pkt_queue 队列
###14. softnet_data.completion_queue
有些时候, 需要延后释放sk_buff (例如在中断上下文中, 需要快速返回),可以将需要释放的的sk_buff添加到 softnet_data.completion_queue 链表中, 在 net_device 的软中断NET_TX_SOFTIRQ 的处理函数 net_tx_action()中, 会释放softnet_data.completion_queue中的所有 sk_buff
例如, 在dev_kfree_skb_irq()中,并不执行实际的释放工作, 只是将需要释放的的sk_buff添加到 softnet_data.completion_queue 链表中, 然后触发 NET_TX_SOFTIRQ 软中断来处理
